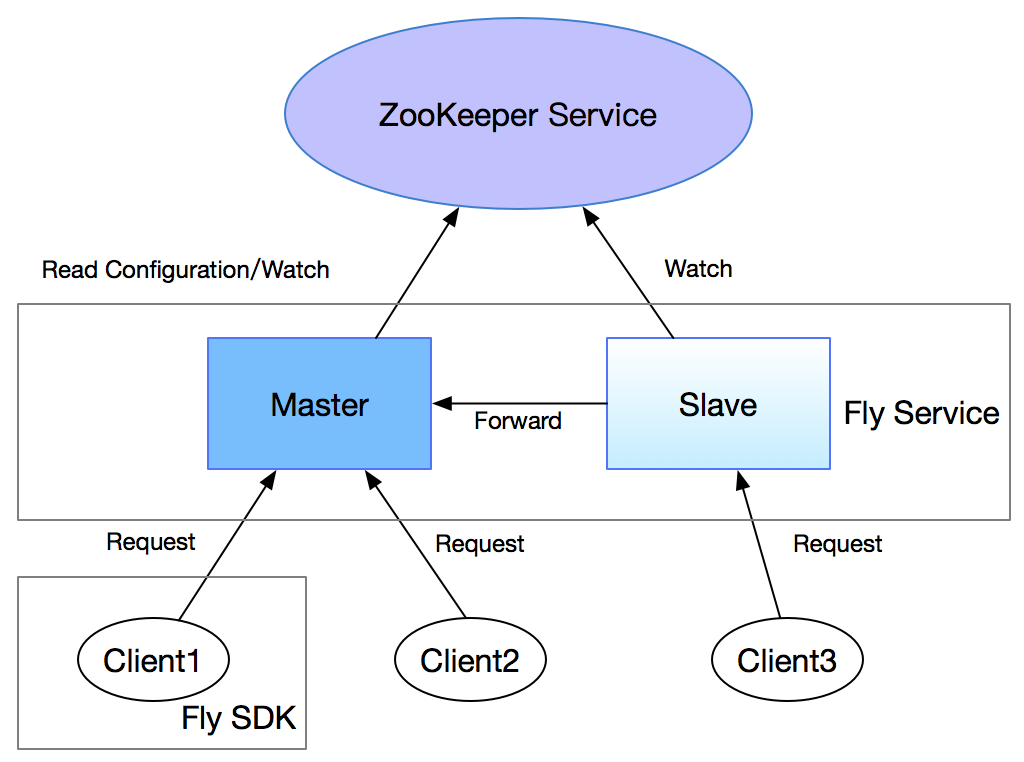
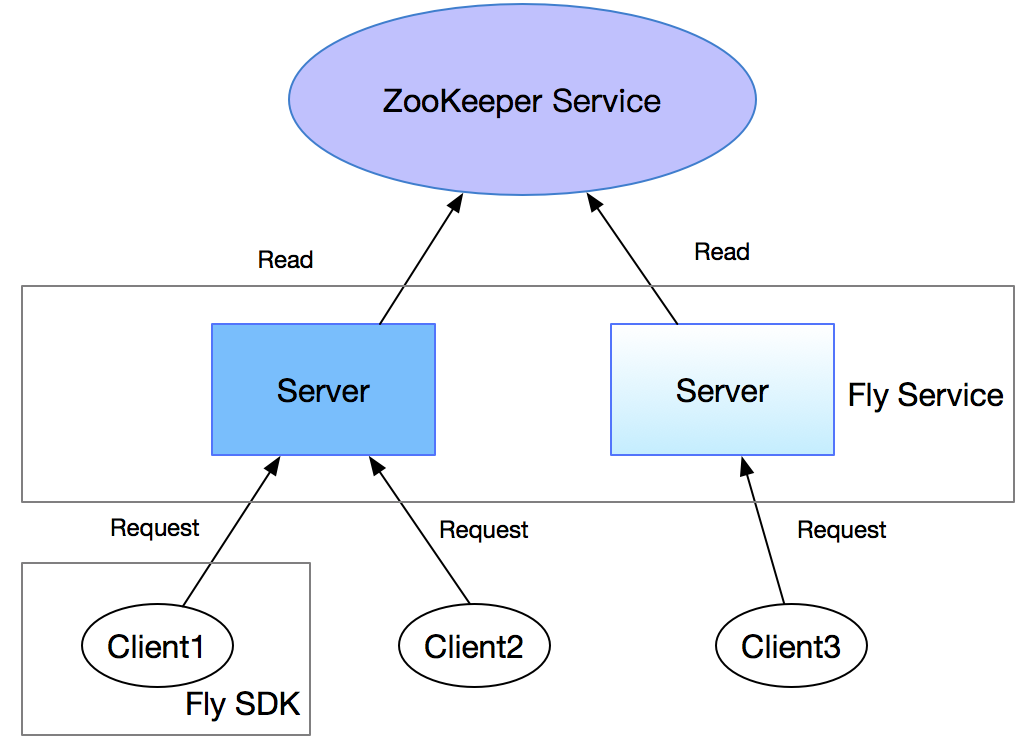
序言
日常开发中,经常会接触定时任务,比如数据同步,数据的聚合,报表发送等等。目前常用的调度第三方库有Spring-Schedule,Quartz等,本文主要介绍Spring-Schedule的调度实现。
示例
首先pom里引入依赖:
下图的代码片段是一个使用Spring库进行调度的例子,对调度的service方法配置cron表达式实现定时执行。
设计与实现
@EnableScheduling注解里注册了ScheduledAnnotationBeanPostProcessor,该BeanPostProcessor里有如下几个重要方法:
- postProcessAfterInitialization
- finishRegistration
- postProcessBeforeDestruction
任务采集 — postProcessAfterInitialization
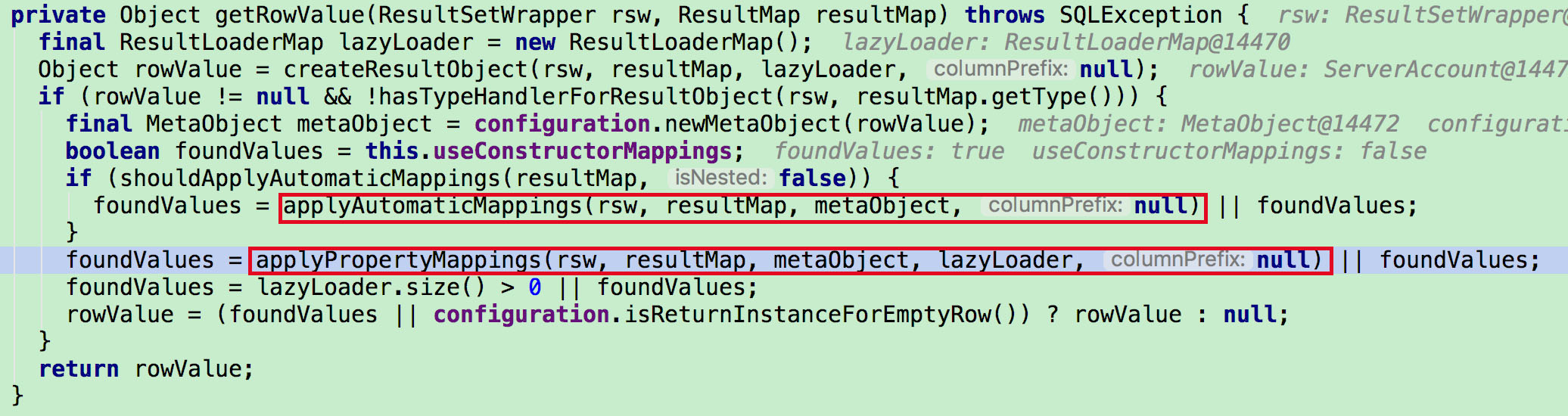
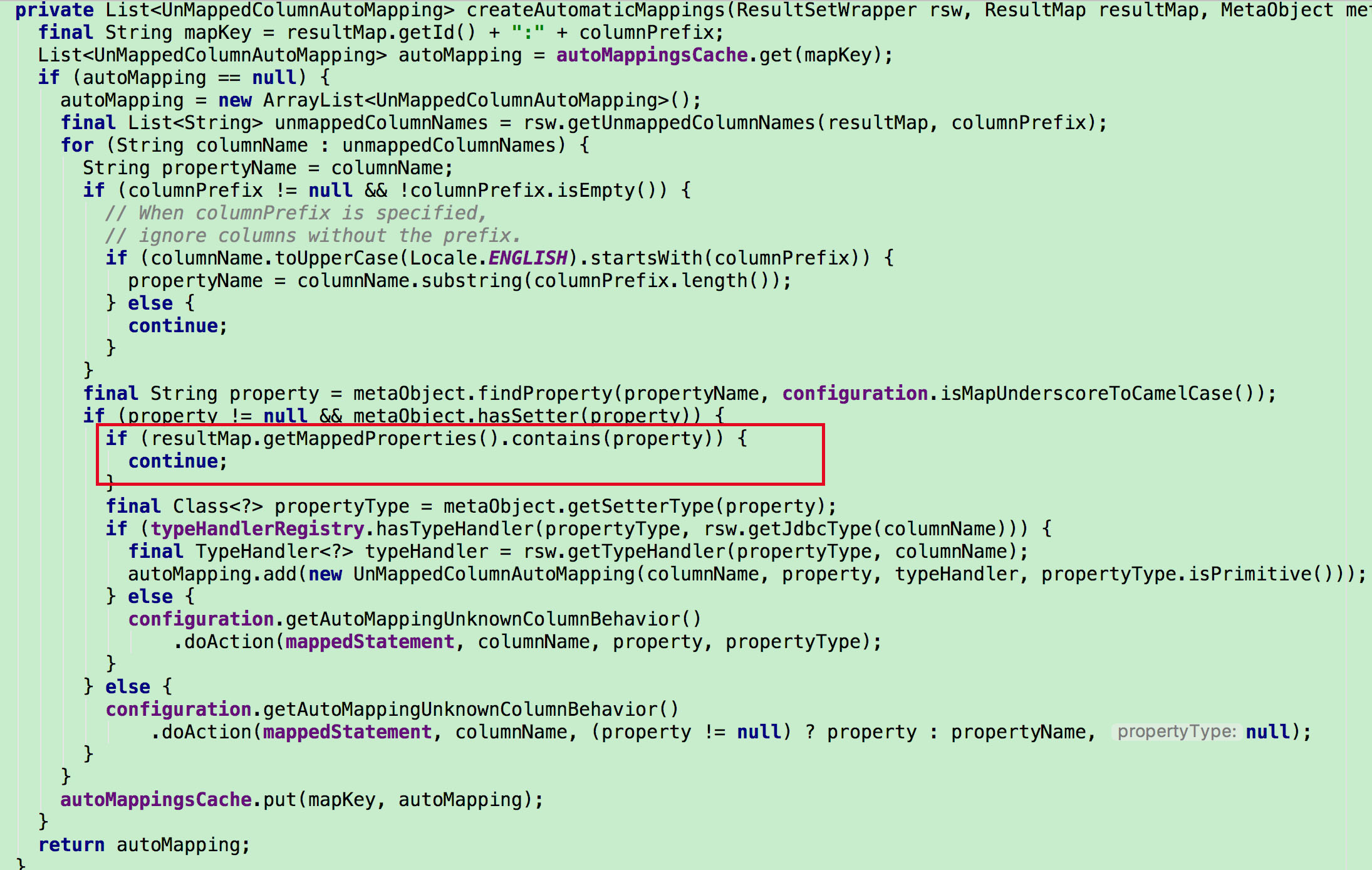
在实例化出Bean,并对Bean进行初始化后,会进入该postProcess方法,对Bean里@Scheduled注解的方法进行解析。(注意同一个方法可能会有多个@Scheduled注解)按照@Scheduled的配置会包装成不同的Task,比如CronTask、IntervalTask。ScheduledTaskRegistrar会对任务容器启动中收集的任务进行暂存,在容器刷新事件发布后,用来启动任务。这里列出了Task的类图: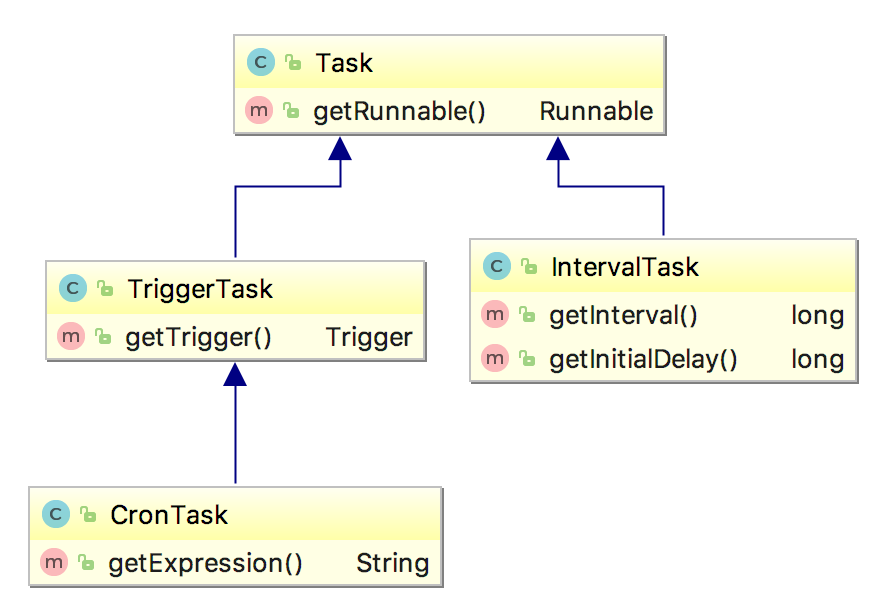
任务注册与启动 — finishRegistration
Spring应用启动完成后,会发布ContextRefreshedEvent,ScheduledAnnotationBeanPostProcessor在onApplicationEvent方法里会对Bean实例化期间收集的调度任务进行启动。
任务的注册启动涉及三个组件:
- Task (调度方法/Bean的包装类-ScheduledMethodRunnable)
- Trigger (调度表达式包装类-CronTrigger/PeriodicTrigger)
- ScheduledExecutorService (调度线程池-JDK实现)
任务主要分为两种:间隔执行任务,Cron执行任务。间隔执行任务会以如下方式加入到调度线程池执行:
JDK里ScheduledThreadPoolExecutor的实现是,注册任务时将下一次触发时相对于当前的延迟时间计算出来,放入DelayedWorkQueue,线程池里的线程会不停去检查DelayedWorkQueue里可以执行的任务,取出来执行。(即调度线程池默认会保证至少存在1个核心线程,且不允许超时退出)。对于周期性任务,当前执行完成后,会计算下一次执行的延迟时间,再次加入DelayedWorkQueue。
对于Cron执行任务,CronTrigger对Cron表达式实现了解析,用以获取nextExecutionTime。具体实现如下。
在上述的分析里,无论JDK里还是Spring都是同步去执行任务,如果任务执行的时间过长,可能会错过下一次的执行时机。那是否可以支持执行呢,答案是肯定的,Spring-Schedule提供了异步支持。
任务异步执行 — EnableAsync
|
|
如上是异步执行的例子。EnableAsync注解会注册AsyncAnnotationBeanPostProcessor,该BeanPostProcessor会对@Async注解的Bean进行代理,并编织Advice——AnnotationAsyncExecutionInterceptor。在异步任务的默认实现里,执行任务时会创建SimpleAsyncTaskExecutor去执行。SimpleAsyncTaskExecutor的执行方法:
可以看到,每次任务执行时会创建新的线程。注意,实际应用的时候,要考虑任务量和执行时间,以及合理的线程数。
自定义业务逻辑
对于同步或者异步执行的结果如何收集起来呢?比如执行的结果需要推送到消息队列应该怎么实现呢?如果要进行业务抢占呢?
- 解决方案
既然Spring-Scheduler的异步实现中能对Bean进行功能编织,我们亦可以对方法进行推送和抢占逻辑的增强。
任务销毁 — postProcessBeforeDestruction
当应用停掉的时候,任务也应该进行相应的关闭。以下为调度任务的取消:
总结
本文梳理了Spring的调度实现,但该调度实现为单机的,很多场景下应用是集群部署的,任务还需要抢占执行。分布式的调度实现会在后续的博文中继续分析。